Semantic relatedness
From Wikipedia, the free encyclopedia
Computational Measures of Semantic Relatedness are publicly available means for approximating the relative meaning of words/documents. These have been used for essay-grading by the Educational Testing Service, search engine technology, predicting which links people are likely to click on, etc.
- LSA (Latent semantic analysis) (+) vector-based, adds vectors to measure multi-word terms; (-) non-incremental vocabulary, long pre-processing times
- PMI (Pointwise Mutual Information) (+) large vocab, because it uses any search engine (like Google); (-) cannot measure relatedness between whole sentences or documents
- SOC-PMI (Second Order Co-occurrence PMI) (+) sort lists of important neighbor words from a large corpus; (-) cannot measure relatedness between whole sentences or documents
- GLSA (Generalized Latent Semantic Analysis) (+) vector-based, adds vectors to measure multi-word terms; (-) non-incremental vocabulary, long pre-processing times
- ICAN (Incremental Construction of an Associative Network) (+) incremental, network-based measure, good for spreading activation, accounts for second-order relatedness; (-) cannot measure relatedness between multi-word terms, long pre-processing times
- NGD (Normalized Google Distance; see below) (+) large vocab, because it uses any search engine (like Google); (-) cannot measure relatedness between whole sentences or documents
- WordNet: (+) humanly constructed; (-) humanly constructed (not automatically learned), cannot measure relatedness between multi-word term, non-incremental vocabulary
- ESA (Explicit Semantic Analysis) based on Wikipedia and the ODP
- n° of Wikipedia (noW), inspired by the game Six Degree of Wikipedia, is a distance metric based on the hierarchical structure of Wikipedia. A directed-acyclic graph is first constructed and later, Dijkstra's shortest path algorithm is employed to determine the noW value between two terms as the geodesic distance between the corresponding topics (i.e. nodes) in the graph. Demo is available here.
- VGEM (Vector Generation of an Explicitly-defined Multidimensional Semantic Space) (+) incremental vocab, can compare multi-word terms (-) performance depends on choosing specific dimensions
- BLOSSOM (Best path Length On a Semantic Self-Organizing Map) (+) uses a Self Organizing Map to reduce high dimensional spaces, can use different vector representations (VGEM or word-document matrix), provides 'concept path linking' from one word to another (-) highly experimental, requires nontrivial SOM calculation
Contents |
[edit] Semantic similarity measures
[edit] SimRank
[edit] Google distance
Google distance is a measure of semantic interrelatedness derived from the number of hits returned by the Google search engine for a given set of keywords. Keywords with the same or similar meanings in a natural language sense tend to be "close" in units of Google distance, while words with dissimilar meanings tend to be farther apart.
Specifically, the normalized Google distance between two search terms x and y is

where M is the total number of web pages searched by Google; f(x) and f(y) are the number of hits for search terms x and y, respectively; and f(x, y) is the number of web pages on which both x and y occur.
If the two search terms x and y never occur together on the same web page, but do occur separately, the normalized Google distance between them is infinite. If both terms always occur together, their NGD is zero.
[edit] SOC-PMI
Second Order Co-occurrence PMI (SOC-PMI) (Islam and Inkpen, 2006) word similarity method uses Pointwise Mutual Information to sort lists of important neighbor words of the two target words from a large corpus. PMI-IR used AltaVista's Advanced Search query syntax to calculate probabilities. Note that the ``NEAR" search operator of AltaVista is an essential operator in the PMI-IR method. However, it is no longer in use in AltaVista; this means that, from the implementation point of view, it is not possible to use the PMI-IR method in the same form in new systems. In any case, from the algorithmic point of view, the advantage of using SOC-PMI is that it can calculate the similarity between two words that do not co-occur frequently, because they co-occur with the same neighboring words. We used the British National Corpus (BNC) as a source of frequencies and contexts. The method considers the words that are common in both lists and aggregate their PMI values (from the opposite list) to calculate the relative semantic similarity. We define the pointwise mutual information function for only those words having fb(ti,w) > 0,

where ft(ti) tells us how many times the type ti appeared in the entire corpus, fb(ti,w) tells us how many times word ti appeared with word w in a context window and m is total number of tokens in the corpus. Now, for word w, we define a set of words, Xw, sorted in descending order by their PMI values with w and taken the top-most β words having fpmi(ti,w) > 0. \par  , where
, where 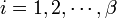 and
and 
A rule of thumb is used to choose the value of β We define the β-PMI summation function of a word with respect to another word. The β-PMI summation function for word w1 with respect to word w2 is: 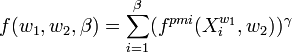 where,
where,  which sums all the positive PMI values of words in the set
which sums all the positive PMI values of words in the set  also common to the words in the set
also common to the words in the set 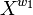 . In other words, this function actually aggregates the positive PMI values of all the semantically close words of w2 which are also common in w1's list. γ should have a value greater than 1. So, the β-PMI summation function for word w1 with respect to word w2 having β = β1 and the β-PMI summation function for word w2 with respect to word w1 having β = β2 are
. In other words, this function actually aggregates the positive PMI values of all the semantically close words of w2 which are also common in w1's list. γ should have a value greater than 1. So, the β-PMI summation function for word w1 with respect to word w2 having β = β1 and the β-PMI summation function for word w2 with respect to word w1 having β = β2 are  and
and
 respectively.
respectively.
Finally, we define the semantic PMI similarity function between the two words, w1 and w2,  We normalize the semantic word similarity, so that it provides a similarity score between 0 and 1 inclusively. The normalization of semantic similarity algorithm returns a normalized score of similarity between two words. It takes as arguments the two words, ri and sj, and a maximum value, λ, that is returned by the semantic similarity function, Sim(). It returns a similarity score between 0 and 1 inclusively. For example, the algorithm returns 0.986 for words cemetery and graveyard with λ = 20 (for SOC-PMI method).
We normalize the semantic word similarity, so that it provides a similarity score between 0 and 1 inclusively. The normalization of semantic similarity algorithm returns a normalized score of similarity between two words. It takes as arguments the two words, ri and sj, and a maximum value, λ, that is returned by the semantic similarity function, Sim(). It returns a similarity score between 0 and 1 inclusively. For example, the algorithm returns 0.986 for words cemetery and graveyard with λ = 20 (for SOC-PMI method).
[edit] See also
[edit] References
- Cilibrasi, R. & Vitanyi, P.M.B. (2006). Similarity of objects and the meaning of words. Proc. 3rd Conf. Theory and Applications of Models of Computation (TAMC), J.-Y. Cai, S. B. Cooper, and A. Li (Eds.), Lecture Notes in Computer Science, Vol. 3959, Springer-Verlag, Berlin.
- Dumais, S. (2003). Data-driven approaches to information access. Cognitive Science, 27(3), 491-524.
- Gabrilovich, E. and Markovitch, S. (2007). "Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis", Proceedings of The 20th International Joint Conference on Artificial Intelligence (IJCAI), Hyderabad, India, January 2007. [1]
- Islam, A. and Inkpen, D. (2008). Semantic text similarity using corpus-based word similarity and string similarity. ACM Trans. Knowl. Discov. Data 2, 2 (Jul. 2008), 1-25. DOI= http://doi.acm.org/10.1145/1376815.1376819
- Islam, A. and Inkpen, D. (2006). Second Order Co-occurrence PMI for Determining the Semantic Similarity of Words, in Proceedings of the International Conference on Language Resources and Evaluation (LREC 2006), Genoa, Italy, pp. 1033-1038. [2]
- Juvina, I., van Oostendorp, H., Karbor, P., & Pauw, B. (2005). Towards modeling contextual information in web navigation. In B. G. Bara & L. Barsalou & M. Bucciarelli (Eds.), 27th Annual Meeting of the Cognitive Science Society, CogSci2005 (pp. 1078-1083). Austin, Tx: The Cognitive Science Society, Inc.
- Kaur, I. & Hornof, A.J. (2005). A Comparison of LSA, WordNet and PMI for Predicting User Click Behavior. Proceedings of the Conference on Human Factors in Computing, CHI 2005 (pp. 51-60).
- Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato's problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104(2), 211-240.
- Landauer, T. K., Foltz, P. W., & Laham, D. (1998). Introduction to Latent Semantic Analysis. Discourse Processes, 25, 259-284.
- Lee, M. D., Pincombe, B., & Welsh, M. (2005). An empirical evaluation of models of text document similarity. In B. G. Bara & L. Barsalou & M. Bucciarelli (Eds.), 27th Annual Meeting of the Cognitive Science Society, CogSci2005 (pp. 1254-1259). Austin, Tx: The Cognitive Science Society, Inc.
- Lemaire, B., & Denhiére, G. (2004). Incremental construction of an associative network from a corpus. In K. D. Forbus & D. Gentner & T. Regier (Eds.), 26th Annual Meeting of the Cognitive Science Society, CogSci2004. Hillsdale, NJ: Lawrence Erlbaum Publisher.
- Lindsey, R., Veksler, V.D., Grintsvayg, A., Gray, W.D. (2007). The Effects of Corpus Selection on Measuring Semantic Relatedness. Proceedings of the 8th International Conference on Cognitive Modeling, Ann Arbor, MI.
- Pirolli, P. (2005). Rational analyses of information foraging on the Web. Cognitive Science, 29(3), 343-373.
- Pirolli, P., & Fu, W.-T. (2003). SNIF-ACT: A model of information foraging on the World Wide Web. Lecture Notes in Computer Science, 2702, 45-54.
- Turney, P. (2001). Mining the Web for Synonyms: PMI versus LSA on TOEFL. In L. De Raedt & P. Flach (Eds.), Proceedings of the Twelfth European Conference on Machine Learning (ECML-2001) (pp. 491-502). Freiburg, Germany.
- Veksler, V.D. & Gray, W.D. (2006). Test Case Selection for Evaluating Measures of Semantic Distance. Proceedings of the 28th Annual Meeting of the Cognitive Science Society, CogSci2006.
- Wong, W., Liu, W. & Bennamoun, M. (2008) Featureless Data Clustering. In: M. Song and Y. Wu; Handbook of Research on Text and Web Mining Technologies; IGI Global. [isbn: 978-1-59904-990-8] (the use of NGD and noW for term and URI clustering)
[edit] Google distance references
- Rudi Cilibrasi and Paul Vitanyi (2004). , The Google Similarity Distance, ArXiv.org or The Google Similarity Distance, IEEE Trans. Knowledge and Data Engineering, 19:3(2007), 370-383..
- Google's search for meaning at Newscientist.com.
- Jan Poland and Thomas Zeugmann (2006), Clustering the Google Distance with Eigenvectors and Semidefinite Programming
- Aarti Gupta and Tim Oates (2007), Using Ontologies and the Web to Learn Lexical Semantics (Includes comparison of NGD to other algorithms.)
- Wong, W., Liu, W. & Bennamoun, M. (2007) Tree-Traversing Ant Algorithm for Term Clustering based on Featureless Similarities. In: Data Mining and Knowledge Discovery, Volume 15, Issue 3, Pages 349-381. [doi: 10.1007/s10618-007-0073-y] (the use of NGD for term clustering)
[edit] External links
- Measures of Semantic Relatedness
- WordNet-Similarity, an open source package for computing the similarity and relatedness of concepts found in WordNet

