Weighted mean
From Wikipedia, the free encyclopedia
The weighted mean is similar to an arithmetic mean (the most common type of average), where instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.
If all the weights are equal, then the weighted mean is the same as the arithmetic mean. While weighted means generally behave in a similar fashion to arithmetic means, they do have a few counter-intuitive properties, as captured for instance in Simpson's paradox.
The term weighted average usually refers to a weighted arithmetic mean, but weighted versions of other means can also be calculated, such as the weighted geometric mean and the weighted harmonic mean.
[edit] Example
Given two school classes, one with 20 students, and one with 30 students, the grades in each class on a test were:
- Morning class = 62, 67, 71, 74, 76, 77, 78, 79, 79, 80, 80, 81, 81, 82, 83, 84, 86, 89, 93, 98
- Afternoon class = 81, 82, 83, 84, 85, 86, 87, 87, 88, 88, 89, 89, 89, 90, 90, 90, 90, 91, 91, 91, 92, 92, 93, 93, 94, 95, 96, 97, 98, 99
The straight average for the morning class is 80 and the straight average of the afternoon class is 90. The straight average of 80 and 90 is 85, the mean of the two class means. However, this does not account for the difference in number of students in each class, and the value of 85 does not reflect the average student grade (independent of class). The average student grade can be obtained by either averaging all the numbers without regard to classes, or weighting the class means by the number of students in each class:
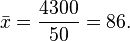
Or, using a weighted mean of the class means:

The weighted mean makes it possible to find the average student grade also in the case where only the class means and the number of students in each class are available.
[edit] Mathematical definition
Formally, the weighted mean of a non-empty set of data
![[x_1, x_2, \dots , x_n]\,,](http://upload.wikimedia.org/math/a/e/c/aec1ac4e26566609cad393c26626ff88.png)
with non-negative weights
![[w_1, w_2, \dots, w_n]\,,](http://upload.wikimedia.org/math/b/d/7/bd78f665a266b74fd304373d44309386.png)
is the quantity calculated by

which means:
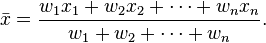
So data elements with a high weight contribute more to the weighted mean than do elements with a low weight. The weights must not be negative. They may be zero, but not all of them (because division by zero is not allowed).
Formulae and calculations become much simpler when normalizing the weights, such that they sum up to 1, i.e. 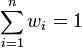 . Normalized weights are easily obtained by dividing each weight by the sum of all weights,
. Normalized weights are easily obtained by dividing each weight by the sum of all weights,  , i.e. by the re-definition
, i.e. by the re-definition  . For normalized weights the weighted mean is simply
. For normalized weights the weighted mean is simply  .
.
The common mean  results as a special case of the weighted mean when all data have equal weights, that is when wi = w.
results as a special case of the weighted mean when all data have equal weights, that is when wi = w.
[edit] Length-weighted mean
For weighting a response variable based upon its dependency on x, a distance variable.
[edit] Convex combination
Since only the relative weights are relevant, any weighted mean can be expressed using coefficients that sum to one. Such a linear combination is called a convex combination.
Using the previous example, we would get the following:



This simplifies to:

[edit] Statistical properties
The weighted sample mean 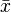 with normalized weights is itself a random variable. How are its expected value and standard deviation related to the expected values and standard deviations of the observations?
with normalized weights is itself a random variable. How are its expected value and standard deviation related to the expected values and standard deviations of the observations?
If the observations have expected values  , then the weighted sample mean has expectation
, then the weighted sample mean has expectation  . Particularly, if the expectations of all observations are equal,
. Particularly, if the expectations of all observations are equal,  , then the expectation of the weighted sample mean is the same,
, then the expectation of the weighted sample mean is the same,  .
.
If the observations have standard deviations σi and are uncorrelated from each other, then the weighted sample mean has standard deviation 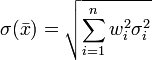 . If moreover the standard deviations of all observations are equal, σi = d, then the weighted sample mean has standard deviation
. If moreover the standard deviations of all observations are equal, σi = d, then the weighted sample mean has standard deviation  , where V2 is the interesting quantity
, where V2 is the interesting quantity 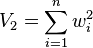 , which is lying in the range
, which is lying in the range 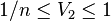 . It attains the minimum for equal weights, and the maximum when all weights except one are zero. In the former case we have
. It attains the minimum for equal weights, and the maximum when all weights except one are zero. In the former case we have 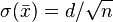 , which textbooks display in the chapter about the central limit theorem.
, which textbooks display in the chapter about the central limit theorem.
[edit] Dealing with variance
For the weighted mean of a list of data for which each element 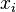 comes from a different probability distribution with known variance
comes from a different probability distribution with known variance 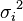 , one possible choice for the weights is given by:
, one possible choice for the weights is given by:

The weighted mean in this case is:

and the variance of the weighted mean is:
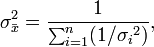
which reduces to  , when all
, when all 
The significance of this choice is that this weighted mean is the maximum likelihood estimator of the mean of the probability distributions under the assumption that they are independent and normally distributed with the same mean.
[edit] Correcting for over/under dispersion
Weighted means are typically used to find the weighted mean of experimental data, rather than theoretically generated data. In this case, there will be some error in the variance of each data point. Typically experimental errors are underestimated because the experimenter does not know all sources of error in calculating the variance of each data point. In this event, the variance in the weighted mean must be corrected to account for the fact that χ2 is too large. The correction that must be made is

where 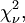 is χ2, divided by the number of degrees of freedom, in this case n − 1,. This gives the variance in the weighted mean as:
is χ2, divided by the number of degrees of freedom, in this case n − 1,. This gives the variance in the weighted mean as:
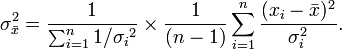
[edit] Weighted sample variance
Typically when you calculate a mean it is important to know the variance and standard deviation of that mean. When a weighted mean μ * with normalized weights is used, the variance of the weighted sample is different from the variance of the unweighted sample. The biased weighted sample variance is defined similarly to the normal biased sample variance:


For small sample of populations, it is customary to use an unbiased estimator for the population variance. In normal unweighted samples, the N in the denominator (corresponding to the sample size) is changed to N − 1. While this is simple in unweighted samples, it becomes tedious for weighted samples. Thus, the unbiased estimator of weighted population variance is given by [1]:
 ,
,
where V2 was introduced in a previous section. The degrees of freedom of the weighted, unbiased sample variance vary accordingly from N − 1 down to 0.
The standard deviation is simply the square root of the variance above.
[edit] Accounting for correlations
In the general case, suppose that ![\mathbf{X}=[x_1,\dots,x_n]](http://upload.wikimedia.org/math/2/6/3/2636af2ccd97baf04c3d1bb68299694e.png) ,
,  is the covariance matrix relating the quantities xi, is the common mean to be estimated, and
is the covariance matrix relating the quantities xi, is the common mean to be estimated, and  is the design matrix [1, ..., 1] (of length n). The Gauss–Markov theorem says that the estimate of the mean having minimum variance is given by:
is the design matrix [1, ..., 1] (of length n). The Gauss–Markov theorem says that the estimate of the mean having minimum variance is given by:

and

[edit] Decreasing strength of interactions
Consider the time series of an independent variable x and a dependent variable y, with n observations sampled at discrete times ti. In many common situations, the value of y at time ti depends not only from xi but also from its past values. It is again most common, that the strength of this dependence decreases as the distance in time increases. To model this situation, one may replace the independent variable by its sliding mean z with window size m.
| Weighted Mean Equivalence | Range (1-5) |
|---|---|
| Strong | 3.34 - 5.00 |
| Satisfactory | 1.67 - 3.33 |
| Weak | 0.00 - 1.66 |
[edit] Exponentially decreasing weights
In the scenario of the previous section, most frequently the decrease of interaction strength obeys a negative exponential law. If the observations are sampled at equidistant times, then exponential decrease is equivalent to decrease by a constant fraction 0 < Δ < 1 at each time step. Setting w = 1 − Δ we can define m normalized weights by 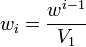 . where V1, the sum of the unnormalized weights, is in this case simply
. where V1, the sum of the unnormalized weights, is in this case simply  , approaching V1 = 1 / (1 − w) for large values of m.
, approaching V1 = 1 / (1 − w) for large values of m.
The damping constant w must fit the factual decrease of interaction strength. If it cannot be determined from theoretical considerations, then the following nice properties of exponentially decreasing weights are useful to take a suitable choice: at step (1 − w) − 1, the weight approximately equals e − 1(1 − w) = 0.39(1 − w), the tail area the value e − 1, the head area 1 − e − 1 = 0.61. The tail area at step n is 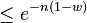 . If mainly the closest n observations matter and the effect of the remaining observations can be ignored safely, then choose w such that the tail area is sufficiently small.
. If mainly the closest n observations matter and the effect of the remaining observations can be ignored safely, then choose w such that the tail area is sufficiently small.
[edit] See also
- Average
- Summary statistics
- Central tendency
- Weighted least squares
- Weighted average cost of capital
- Weighting
[edit] References
- Bevington, Philip. Data Reduction and Error Analysis for the Physical Sciences.

