Bayesian spam filtering
From Wikipedia, the free encyclopedia
Bayesian spam filtering (pronounced BAYS-ee-ən, IPA pronunciation: ['beɪz.i.ən], after Rev. Thomas Bayes), a form of e-mail filtering, is the process of using a Naive Bayesian classifier to identify spam e-mail. It is one of the techniques of statistical e-mail filtering.
The first known mail-filtering program to use a Bayes classifier was Jason Rennie's iFile program, released in 1996. The program was used to sort mail into folders.[1] The first scholarly publication on Bayesian spam filtering was by Sahami et al. (1998).[2] Variants of the basic technique have been implemented in a number of research works and commercial software products.[citation needed] In 2002, the principles of Bayesian filtering were publicized to more general audiences in an essay by Paul Graham.[3]
Bayesian spam filtering has become a popular mechanism to distinguish illegitimate spam email from legitimate email (sometimes called "ham" or "bacn").[4] Many modern mail clients implement Bayesian spam filtering. Users can also install separate email filtering programs. Server-side email filters, such as DSPAM, SpamAssassin, SpamBayes, Bogofilter and ASSP, make use of Bayesian spam filtering techniques, and the functionality is sometimes embedded within mail server software itself.
Contents |
[edit] Process
Particular words have particular probabilities of occurring in spam email and in legitimate email. For instance, most email users will frequently encounter the word "Viagra" in spam email, but will seldom see it in other email. The filter doesn't know these probabilities in advance, and must first be trained so it can build them up. To train the filter, the user must manually indicate whether a new email is spam or not. For all words in each training email, the filter will adjust the probabilities that each word will appear in spam or legitimate email in its database. For instance, Bayesian spam filters will typically have learned a very high spam probability for the words "Viagra" and "refinance", but a very low spam probability for words seen only in legitimate email, such as the names of friends and family members.
After training, the word probabilities (also known as likelihood functions) are used to compute the probability that an email with a particular set of words in it belongs to either category. Each word in the email contributes to the email's spam probability, or only the most interesting words. This contribution is called the posterior probability and is computed using Bayes' theorem.
Then, the email's spam probability is computed over all words in the email, and if the total exceeds a certain threshold (say 95%), the filter will mark the email as a spam. Email marked as spam can then be automatically moved to a "Junk" email folder, or even deleted outright. Some software implement quarantine mechanisms that define a time frame during which the user is allowed to review the software's decision.
The initial training can usually be refined when wrong judgements from the software are identified (false positives or false negatives). That allows the software to dynamically adapt to the ever evolving nature of spam.
Some spam filters combine the results of both Bayesian spam filtering and other heuristics (pre-defined rules about the contents, looking at the message's envelope, etc.), resulting in even higher filtering accuracy, sometimes at the cost of adaptiveness.
[edit] Mathematical foundation
Bayesian email filters take advantage of Bayes' theorem. Bayes' theorem is used several times in the context of spam:
- a first time, to compute the probability that the message is spam, knowing that a given word appears in this message;
- a second time, to compute the probability that the message is spam, taking into consideration all of its words (or a relevant subset of them);
- sometimes a third time, to deal with rare words.
[edit] Computing the probability that a message containing a given word is spam
Let's suppose the suspected message contains the word "Replica". Most people who are used to receiving e-mail know that this message is likely to be spam, more precisely a proposal to sell counterfeit copies of well-known brands of watches. The spam detection software, however, does not "know" such facts, all it can do is compute probabilities.
The formula that the software uses to determine that is derived from Bayes' theorem. It is, in its most general form:

where:
- Pr(S | W) is the probability that a message is a spam, knowing that the word "replica" is in it;
- Pr(S) is the overall probability that any given message is spam;
- Pr(W | S) is the probability that the word "replica" appears in spam messages;
- Pr(H) is the overall probability than any given message is not spam (is "ham");
- Pr(W | H) is the probability that the word "replica" appears in ham messages.
(Demonstration : see Bayes' theorem#Alternative forms of Bayes' theorem)
[edit] The spamicity (or spaminess)
Recent statistics show that current probability of any message to be spam is 80%, at the very least:
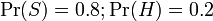
However, most bayesian spam detection software make the assumption that there is no a priori reason for any incoming message to be spam rather than ham, and consider both cases to have equal probabilities of 50%:

The filters that use this hypothesis are said to be "not biased", meaning that they have no prejudice regarding the incoming email. This assumption allows to simplify the general formula to:
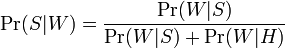
This quantity is called "spamicity" (or "spaminess") of the word "replica", and can be computed. The number Pr(W | S) used in this formula is approximated to the frequency of messages containing "replica" in the messages identified as spam during the learning phase. Similarly, Pr(W | H) is approximated to the frequency of messages containing "replica" in the messages identified as ham during the learning phase. For these approximations to make sense, the set of learned messages needs to be big and representative enough. It is also advisable that the learned set of messages conforms to the 50% hypothesis about repartition between spam and ham, i.e. that spam and ham corpuses are of same size.
Of course, determining whether a message is spam or ham based only on the presence of the word "replica" is error-prone, that's why bayesian spam software tries to consider several words and combine their spamicities to determine its overall probability of being a spam.
[edit] Combining individual probabilities
The bayesian spam filtering software makes the "naive" assumption that the words present in the message are independent events. That is wrong in natural languages like English, where the probability of finding an adjective, for example, is affected by the probability of having a noun. Anyway, with that assumption, one can derive another formula from Bayes' theorem:
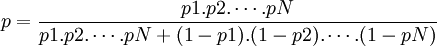
where:
- p is the probability that the suspect message is spam;
- p1 is the probability p(S | W1) that it is a spam knowing it contains a first word (for example "replica");
- p2 is the probability p(S | W2) that it is a spam knowing it contains a second word (for example "watches");
- etc...
- pN is the probability p(S | WN) that it is a spam knowing it contains a Nth word (for example "home").
(Demonstration: [5])
Such assumptions make the spam filtering software a naive Bayes classifier.
The result p is usually compared to a given threshold to decide whether the message is spam or not. If p is lower than the threshold, the message is considered as likely ham, otherwise it is considered as likely spam.
[edit] Dealing with rare words
In the case a word has never been met during the learning phase, both the numerator and the denominator are equal to zero, both in the general formula and in the spamicity formula. The software can decide to discard such words for which there is no information available.
More generally, the words that were encountered only a few times during the learning phase cause a problem, because it would be an error to trust blindly the information they provide. A simple solution is to simply avoid taking such unreliable words into account as well.
Applying again Bayes' theorem, and assuming the classification between spam and ham of the emails containing a given word ("replica") is a random variable with beta distribution, some other software decide to use a corrected probability:
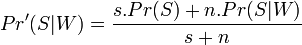
where:
- Pr'(S | W) is the corrected probability for the message to be spam, knowing that it contains a given word ;
- s is the strength we give to background information about incoming spam ;
- Pr(S) is the probability of any incoming message to be spam ;
- n is the number of occurencies of this word during the learning phase ;
- Pr(S | W) is the spamicity of this word.
(Demonstration: [6])
This corrected probability is used instead of the spamicity in the combining formula.
Pr(S) can again be taken equal to 0.5, to avoid being too suspicious about incoming email. 3 is a good value for s, meaning that the learned corpus must contain more than 3 messages with that word to put more confidence in the spamicity value than in the default value.
This formula can be extended to the case where n is equal to zero (and where the spamicity is not defined), and evaluates in this case to Pr(S).
[edit] Other heuristics
"Neutral" words like "the", "a", "some", or "is" (in English), or their equivalents in other languages, can be ignored. More generally, some bayesian filtering filters simply ignore all the words which have a spamicity next to 0.5, as they bring little to a good decision. The words taken into consideration are those whose spamicity is next to 0.0 (distinctive signs of legitimate messages), or next to 1.0 (distinctive signs of spam). A method can be for example to keep only those ten words, in the examined message, which have the greatest absolute value | 0.5 − pI | .
Some software products take into account the fact that a given word appears several times in the examined message [7], others don't.
Some software products use patterns (sequences of words) instead of isolated natural languages words[8]. For example, with a "context window" of four words, they compute the spamicity of "Viagra is good for", instead of computing the spamicities of "Viagra", "is", "good", and "for". This method gives more sensitivity to context and eliminates the Bayesian noise better, at the expense of a bigger database.
[edit] Mixed methods
There are other ways of combining individual probabilities for different words than using the "naive" approach. These methods differ from it on the assumptions they make on the statistical properties of the input data. These different hypothesis result in radically different formulas for combining the individual probabilities.
For example, assuming the individual probabilities follow a chi-square distribution with 2.N degrees of freedom, one could use the formula:

where C − 1 is the inverse of the chi-square function.
Individual probabilities can be combined with the techniques of the Markovian discrimination too.
[edit] Discussion
[edit] Advantages
The advantage of Bayesian spam filtering is that it can be trained on a per-user basis.
The spam that a user receives is often related to the online user's activities. For example, a user may have been subscribed to an online newsletter that the user considers to be spam. This online newsletter is likely to contain words that are common to all newsletters, such as the name of the newsletter and its originating email address. A Bayesian spam filter will eventually assign a higher probability based on the user's specific patterns.
The legitimate e-mails a user receives will tend to be different. For example, in a corporate environment, the company name and the names of clients or customers will be mentioned often. The filter will assign a lower spam probability to emails containing those names.
The word probabilities are unique to each user and can evolve over time with corrective training whenever the filter incorrectly classifies an email. As a result, Bayesian spam filtering accuracy after training is often superior to pre-defined rules.
It can perform particularly well in avoiding false positives, where legitimate email is incorrectly classified as spam. For example, if the email contains the word "Nigeria", which is frequently used in Advance fee fraud spam, a pre-defined rules filter might reject it outright. A Bayesian filter would mark the word "Nigeria" as a probable spam word, but would take into account other important words that usually indicate legitimate e-mail. For example, the name of a spouse may strongly indicate the e-mail is not spam, which could overcome the use of the word "Nigeria."
[edit] Disadvantages
Bayesian spam filtering is susceptible to Bayesian poisoning, a technique used by spammers in an attempt to degrade the effectiveness of spam filters that rely on Bayesian filtering. A spammer practicing Bayesian poisoning will send out emails with large amounts of legitimate text (gathered from legitimate news or literary sources). Spammer tactics include insertion of random innocuous words that are not normally associated with spam, thereby decreasing the email's spam score, making it more likely to slip past a Bayesian spam filter.
Another technique used to try to defeat bayesian spam filters is to replace text with pictures, either directly included or linked. The whole text of the message, or some part of it, is replaced with a picture where the same text is "drawn". The spam filter is usually unable to analyse this picture, which would contain the sensitive words like "Viagra". However, since many mail clients disable the display of linked pictures for security reasons, the spammer sending links to distant pictures might reach fewer targets. Also, a picture's size in bytes is bigger than the equivalent text's size, so the spammer needs more bandwidth to send messages directly including pictures. Finally, some filters are more inclined to decide that a message is spam if it has mostly graphical contents.
[edit] General applications of Bayesian filtering
While Bayesian filtering is used widely to identify spam email, the technique can classify (or "cluster") almost any sort of data. It has uses in science, medicine, and engineering. One example is a general purpose classification program called AutoClass which was originally used to classify stars according to spectral characteristics that were otherwise too subtle to notice. There is recent speculation that even the brain uses Bayesian methods to classify sensory stimuli and decide on behavioural responses.[9]
[edit] See also
- Bayesian poisoning
- Bayesian inference
- Bayes's theorem
- Email filtering
- Markovian discrimination
- Naive Bayes classifier
- Recursive Bayesian estimation
- Stopping e-mail abuse
[edit] References
- ^ Jason Rennie (1996). "ifile". http://people.csail.mit.edu/jrennie/ifile/old/README-0.1A.
- ^ M. Sahami, S. Dumais, D. Heckerman, E. Horvitz (1998). "A Bayesian approach to filtering junk e-mail". AAAI'98 Workshop on Learning for Text Categorization. http://robotics.stanford.edu/users/sahami/papers-dir/spam.pdf.
- ^ Graham, Paul (2002). "A Plan for Spam". http://www.paulgraham.com/spam.html.
- ^ "Word Spy - Ham". http://www.wordspy.com/words/ham.asp.
- ^ "Combining probabilities". http://www.mathpages.com/home/kmath267.htm.
- ^ Gary Robinson (2003). "A statistical approach to the spam problem". http://www.linuxjournal.com/article/6467.
- ^ Brian Burton (2003). "SpamProbe - Bayesian Spam Filtering Tweaks". http://spamprobe.sourceforge.net/paper.html.
- ^ Jonathan A. Zdziarski (2004). "Bayesian Noise Reduction: Contextual Symmetry Logic Utilizing Pattern Consistency Analysis". http://bnr.nuclearelephant.com/l.
- ^ Trends in Neuroscience, 27(12):712-9, 2004 (pdf)
[edit] External links
- Guide to Bayesian spam filters: part 1, part 2.
- Detailed explanation of Paul Graham's formulas by Tim Peters
- Gary Robinson's spam blog
- Why Bayesian filtering is the most effective anti-spam technology
- Article on the benefits of Bayesian spam filtering

